



详细内容
一、一段话总结
本研究通过分析美国国家健康与营养检查调查(NHANES,2013-2023)的 26289 个样本及中国健康与养老追踪调查(CHARLS,2011-2020)的 19328 个外部验证样本,系统探索 49 项常规健康指标与心血管疾病、糖尿病、肝病、癌症及共病(肾病、慢性支气管炎等)的关联;先识别出五种疾病各自的 Top10 诊断预测指标,通过 Venn 图筛选出 7 个跨疾病共同核心指标,进而开发出新型复合糖脂指数 GLM7(整合年龄、甘油三酯、空腹血糖、体重指数、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、胰岛素);利用限制性立方样条(RCS)分析确定 GLM7 对不同疾病的风险阈值(整体 > 7.5 时疾病风险显著升高),并构建基于 7 个核心指标的极端梯度提升(XGBoost)模型,该模型在 NHANES 训练 / 测试集及 CHARLS 验证集中均表现出优异的预测性能(如糖尿病训练集 auROC 达 0.98、心血管疾病验证集 auROC 达 0.85),最终证实常规指标的有效性并验证 GLM7 在多疾病诊断与预测中的价值,为精准疾病管理提供新工具。
二、文献介绍
| 项目 | 内容 |
| 中文标题 | GLM7—— 一种源自常规健康指标的新型复合糖脂指数,用于增强多种疾病诊断和预测 |
| 发表期刊 | Advanced Science(《先进科学》) |
| 发表时间 | 2025 年(接收日期:2025 年 6 月 9 日,修订日期:2025 年 7 月 24 日,在线发表时间未标注具体日,DOI:10.1002/advs.202510552) |
三、研究背景
- 常规体检的现状与矛盾:健康成人常规体检包含身高、体重、血液生化、血常规、尿常规等基础项目,是人群健康维护的基石,可早期识别健康风险;但当前体检项目不断扩张,部分项目对病理机制的提示价值存疑,既消耗时间与医疗资源,又加重患者经济负担。
- 传统指标的价值与优化需求:传统指标(如血压、胆固醇、血糖)已被证实与心血管疾病、糖尿病等慢性病密切相关,且近年衍生出甘油三酯 - 葡萄糖指数(TYG)、血浆致动脉粥样硬化指数(AIP)等新型衍生指标;但临床仍需区分 "高价值指标" 与 "低贡献指标",避免冗余检测,提升诊断效率。
- 研究缺口:现有研究缺乏对多疾病(心血管、糖尿病、肝病、癌症、共病)的统一指标筛选,且缺乏整合多常规指标的复合指数,难以实现 "一站式" 风险评估,因此需开发更精准、高效的诊断与预测工具。
四、数据来源
本研究采用 "发现队列 + 外部验证队列" 双数据源设计,具体信息如下:
| 数据队列 | 时间范围 | 样本量 | 疾病分布(部分关键疾病) | 排除标准 |
| NHANES(发现队列) | 2013-2023 | 最终纳入 26289 例(初始 56893 例,排除 < 20 岁 22795 例、疾病数据缺失 7809 例) | 心血管疾病 3097 例(11.8%)、糖尿病 5136 例(19.5%)、肝病 1249 例(4.75%)、癌症 2690 例(10.2%)、共病 4582 例(17.4%) | 1. 年龄 < 20 岁;2. 心血管疾病(心衰、中风等)、糖尿病、肝病、癌症、共病(肾病等)数据缺失;3. 关键检测指标(如血脂、血糖)数据不全 |
| CHARLS(外部验证队列) | 2011-2020 | 最终纳入 19328 例 | 心血管疾病 1903 例、糖尿病 1541 例、肝病 853 例、癌症 240 例、共病 880 例 | 同 NHANES,且需符合 CHARLS 数据库标准化数据录入标准 |
注:NHANES 为美国全国性调查,CHARLS 为中国全国性调查,两队列覆盖不同种族与地域,可提升研究结果的外推性。
五、研究框架及详细技术路线图
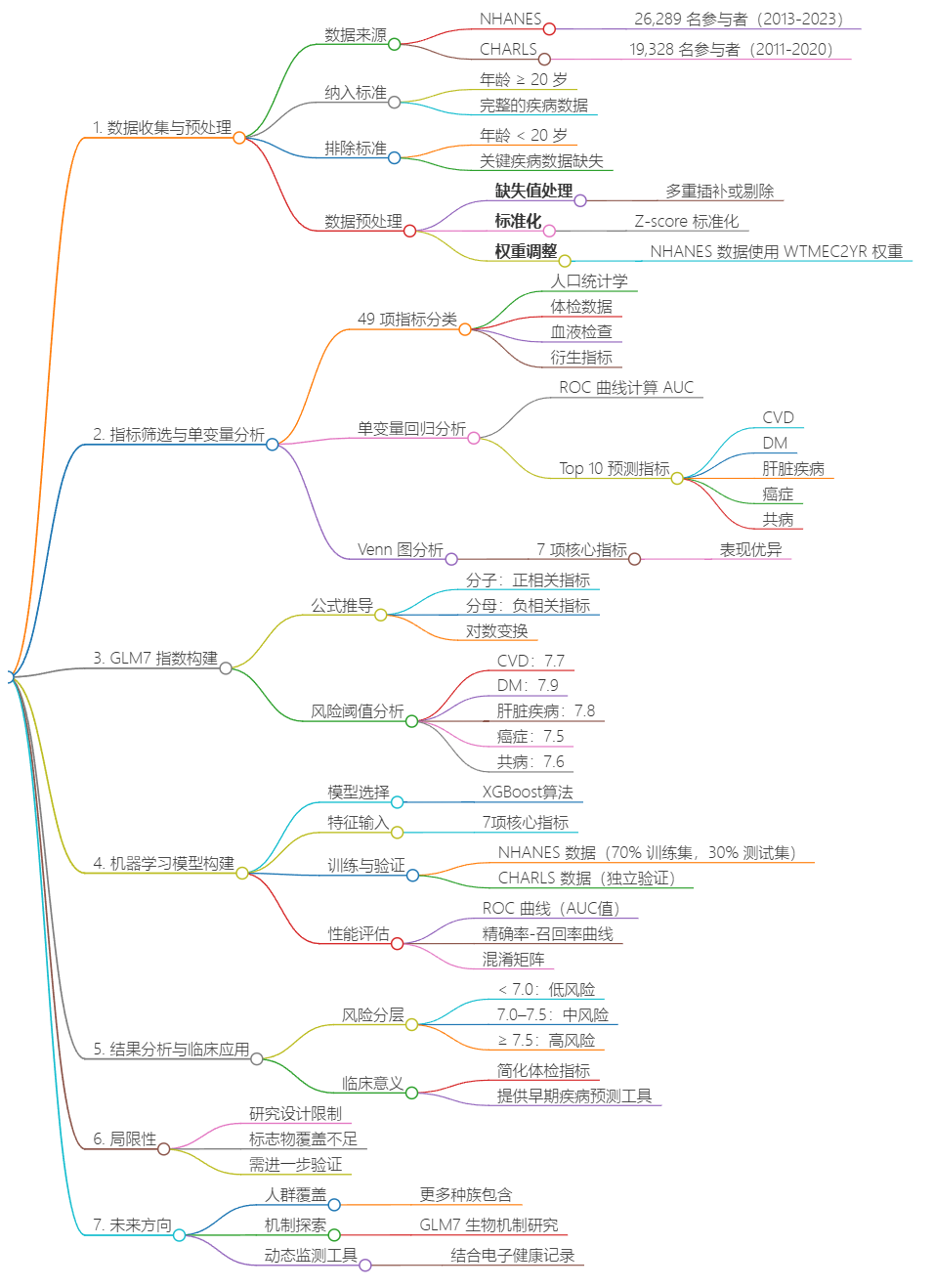
1. 研究整体框架
以 "指标筛选→指数开发→性能验证→模型构建" 为核心逻辑,分三阶段开展研究:
- 第一阶段:指标筛选与核心变量确定;
- 第二阶段:GLM7 复合指数开发与风险阈值分析;
- 第三阶段:机器学习模型构建与跨队列验证。
2. 详细技术路线图
六、研究步骤及结果展示
1. 步骤 1:基线特征分析
- 操作:描述 NHANES 队列的人口学特征(年龄、性别、种族、教育程度、生活习惯)及疾病患病率,并按 GLM7 四分位(<7.0、7.0-7.5、7.5-8.0、>8.0)分层比较。
- 结果:
- 年龄分布:20-44 岁占 40.2%,45-64 岁占 34.8%,≥65 岁占 25%;性别:男性 48.3%;
- 生活习惯:18.9% 重度饮酒,57.7% 不吸烟,56.6% 缺乏运动;
- GLM7 分层差异:随 GLM7 升高,疾病患病率显著上升(如糖尿病:GLM7<7.0 组 5.80% vs>8.0 组 57.6%,p<0.001),所有基线差异均有统计学意义(p<0.05)。
2. 步骤 2:49 项指标的单变量分析与 Top10 指标筛选
- 操作:对 49 项指标(如年龄、TG、LDL-c、TYG 等)进行 ROC 分析,以 AUC 值衡量预测能力,筛选每种疾病的 Top10 指标。
- 结果:
- 跨疾病高价值指标:年龄、LDL-c、TG、胰岛素、TYG、TYG_BMI、AIP 在 5 种疾病中均表现优异(AUC>0.6);
- 各疾病 Top10 代表:
- 心血管疾病:年龄(AUC≈0.70)、LDL-c(AUC≈0.68)、TYG(AUC≈0.67);
- 糖尿病:糖化血红蛋白(HbA1c,AUC≈0.88)、TYG(AUC≈0.80)、胰岛素(AUC≈0.78);
- 肝病:TYG(AUC≈0.75)、AIP(AUC≈0.73)、GGT(AUC≈0.70);
- Venn 图确认 7 个跨疾病共同指标,为 GLM7 开发奠定基础。
3. 步骤 3:GLM7 复合指数开发与关联分析
- 操作:
- 公式推导:基于 7 个基础指标,将 "正向关联指标乘积(年龄、BMI、FBG、胰岛素、TG、LDL-c)" 除以 "负向关联指标(HDL-c)",再经 log10 转换(避免数值过大),公式为:
\(GLM7=log _{10}\left(\frac{年龄(岁) × BMI(kg/m²) × FBG(mg/dL) × 胰岛素 (pmol/L) × TG(mmol/L) × LDL-c(mmol/L)}{HDL-c(mmol/L)}\right)\)
- 单因素 logistic 回归:分析 GLM7 与 5 种疾病的关联强度;
- RCS 分析:探索 GLM7 与疾病的非线性关系及风险阈值。
- 结果:
- GLM7 与疾病的 OR 值(95% CI):
- 心血管疾病:9.98(8.48-11.74);
- 糖尿病:12.19(10.61-14.00);
- 肝病:3.52(2.93-4.22);
- 癌症:3.08(2.70-3.51);
- 共病:3.00(2.70-3.33);
(所有 p<0.001,证实 GLM7 与疾病显著关联)
- RCS 风险阈值:
- 心血管疾病:7.7,糖尿病:7.9,肝病:7.8,癌症:7.5,共病:7.6;
- 整体规律:GLM7>7.5 时,所有疾病风险显著上升(OR 值翻倍)。
4. 步骤 4:GLM7 亚组分析
- 操作:按 GLM7 四分位分层(<7.0、7.0-7.5、7.5-8.0、>8.0),分析不同年龄(20-44 岁、45-64 岁、≥65 岁)和性别亚组的疾病风险。
- 结果:
- GLM7<7.0:各疾病 OR 值 < 1.1(除 65 岁以上糖尿病亚组),风险较低;
- GLM7 7.0-7.5:疾病风险上升,65 岁以上人群风险显著高于年轻人群(如心血管疾病 OR:65 岁以上 1.41 vs 20-44 岁 1.26);
- GLM7 7.5-8.0:风险骤升,所有年龄组 OR 值 > 2(如癌症 OR:45-64 岁 7.76 vs 20-44 岁 2.06);
- GLM7>8.0:心血管 / 糖尿病风险持续升高(OR>11),肝病 / 癌症 / 共病风险趋于稳定(OR≈5);
- 结论:7.5 是 GLM7 的临床关键阈值,且老年人群在相同 GLM7 水平下风险更高。
5. 步骤 5:XGBoost 模型构建与验证
- 操作:
- 模型输入:7 个核心指标(年龄、TG、FBG、BMI、HDL-c、LDL-c、胰岛素);
- 模型训练:NHANES 队列按 7:3 分训练 / 测试集,5 折交叉验证优化超参数(学习率 0.1,树深度 6 等);
- 模型评估:用 auROC(ROC 曲线下面积)、auPRC(精确召回曲线下面积)、混淆矩阵评估性能;
- 外部验证:在 CHARLS 队列中重复评估。
- 结果:
- NHANES 队列性能(训练集 / 测试集 auROC):
- 心血管疾病:0.93/0.85,糖尿病:0.98/0.95,肝病:0.89/0.89,癌症:0.92/0.83,共病:0.92/0.84;
- CHARLS 队列性能(训练集 / 验证集 auROC):
- 心血管疾病:0.913/0.923,糖尿病:0.900/0.895,肝病:0.732/0.728,癌症:0.836/0.790,共病:0.891/0.915;
- 结论:模型在中美人群中均表现优异,auROC 普遍 > 0.8,糖尿病预测效果最佳(auROC>0.89)。
七、研究结论
- 常规指标的价值确认:年龄、TG、LDL-c、FBG 等 7 项常规健康指标是心血管疾病、糖尿病、肝病、癌症及共病的核心预测因子,可作为体检重点项目,减少冗余检测。
- GLM7 的创新价值:新型复合糖脂指数 GLM7 整合 7 项常规指标,对多疾病具有良好诊断与预测能力,且存在明确风险阈值(>7.5 时疾病风险显著升高),可作为临床 "一站式" 风险评估工具。
- 机器学习模型的应用潜力:基于 7 项指标的 XGBoost 模型在 NHANES(美国)和 CHARLS(中国)队列中均表现优异,可整合至电子健康记录系统,实现实时疾病风险评估,助力从 "被动治疗" 向 "主动预防" 转型。
- 研究局限性:
- 基于观察性数据,无法建立因果关系;
- 未纳入非常规生物标志物(如基因、代谢组学指标);
- 对疾病亚型(如不同类型癌症、肝病)的分析不足,未来需进一步细化。
综上,本研究为优化常规体检项目、开发精准疾病预测工具提供了循证依据,对提升人群健康管理效率具有重要临床与公共卫生意义。
